안녕하세요.
오늘은 자바에서 엑셀 파일의 데이터를 추출한 다음, jsp에 보여주는 작업을 정리해보겠습니다.
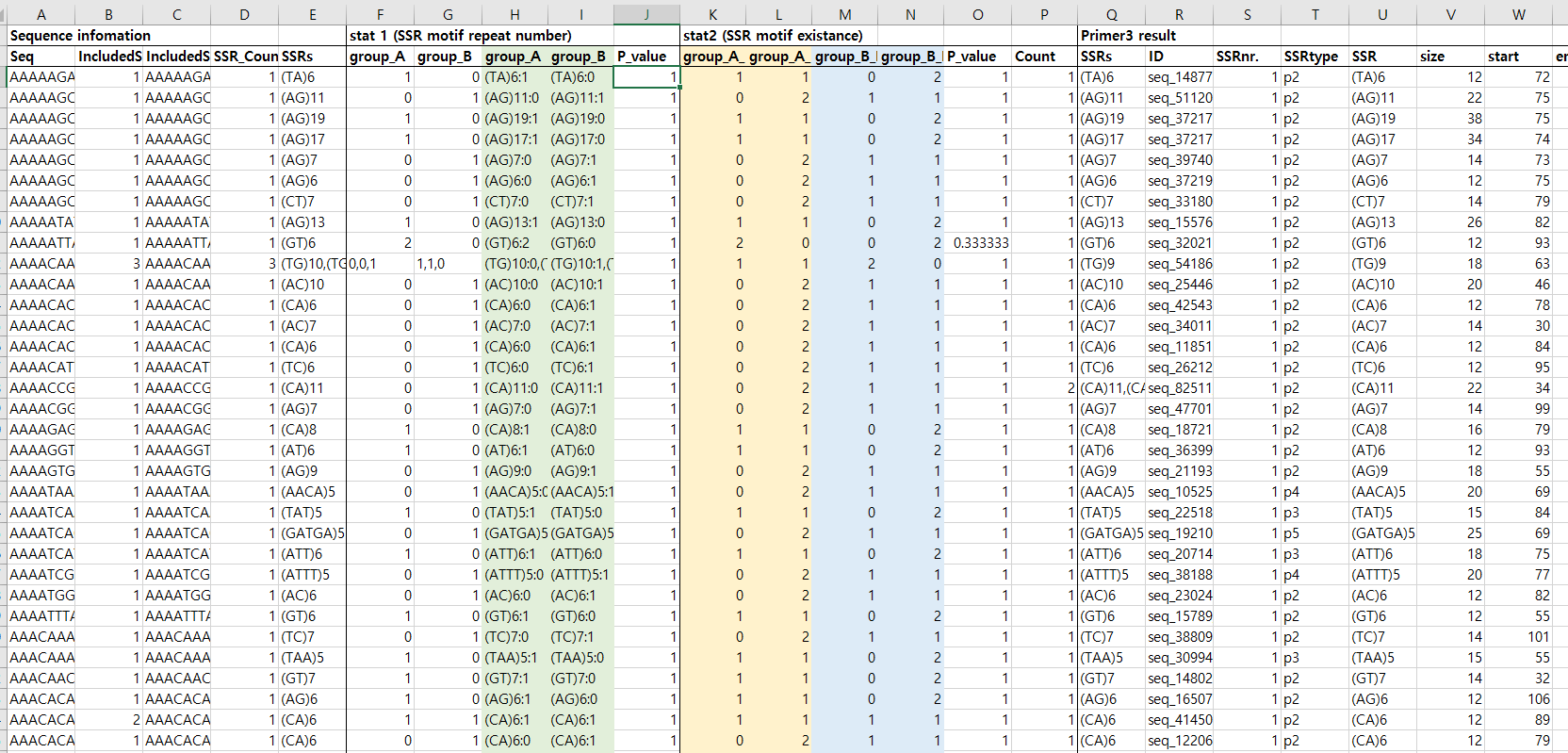
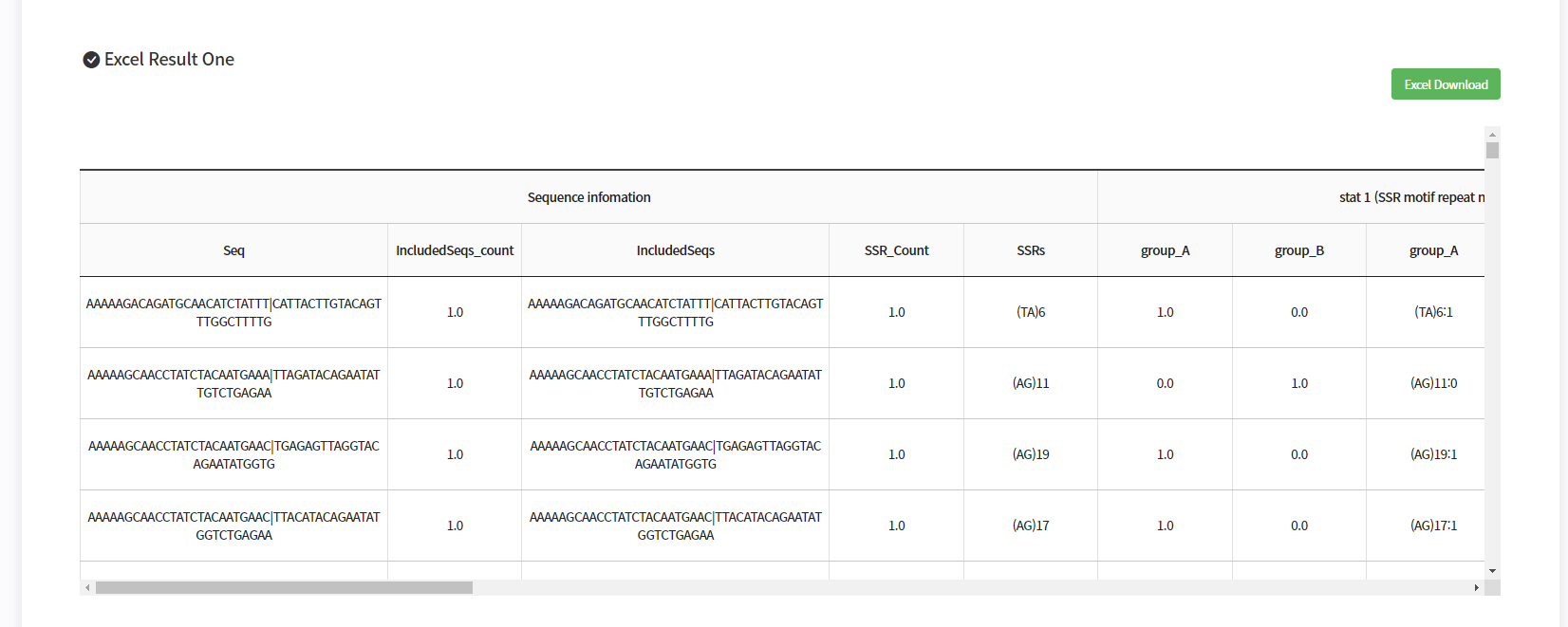
아래 사진과 같이, 엑셀 파일의 데이터를 jsp 테이블에 뿌려주는 거죠!
algorithm
apache POI 라이브러리를 이용하여
자바에서 데이터 추출하여 리스트에 넣어주고
jsp에서 뿌려주기만하면 끝입니다.
Excel File
JSP Table
pom.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.9</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-contrib</artifactId>
<version>3.6</version>
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.9</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>3.9</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>3.9</version>
</dependency>
|
cs |
우선 위존성을 추가해주기 위해서 pom.xml에 poi를 추가해줍니다.
controller
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
@RequestMapping(value="/specimen/store/excelResultOne.do")
public String excelResultOne(
@ModelAttribute("searchVO") storeVO searchVO,
HttpServletRequest request,
HttpSession session,
ModelMap model) throws Exception {
try {
//엑셀 파일 주소를 담습니다. (xls경우)
FileInputStream file = new FileInputStream("C:/file/excelResultOne.xls");
HSSFWorkbook excelfile = new HSSFWorkbook(file);
//xlsx라면 아래 사용 필요합니다.
//XSSFWorkbook workbook = new XSSFWorkbook(file);
HashMap<Integer, String> excelMap = new HashMap<Integer, String>(); // 값을 담을 변수 설정
List<HashMap<Integer, String>> excelList = new ArrayList<HashMap<Integer, String>>(); //값을 담은 맵을 리스트화
int rowindex=0;
int columnindex=0;
DecimalFormat df = new DecimalFormat();
//시트를 읽습니다.
HSSFSheet sheet=excelfile.getSheetAt(0);
//행의 수를 체크해줍니다.
int rows=sheet.getPhysicalNumberOfRows();
for(rowindex=0;rowindex<rows;rowindex++){
if(rowindex > 2) {
excelList.add(excelMap);
excelMap = new HashMap<Integer, String>();
}
//행을 읽습니다.
HSSFRow row=sheet.getRow(rowindex);
if(row !=null){
//셀의 수를 체크해줍니다.
int cells=row.getPhysicalNumberOfCells();
for(columnindex=0; columnindex<=cells-1; columnindex++){
//셀값을 확인합니다.
HSSFCell cell=row.getCell(columnindex);
String value="";
if(cell==null){
excelMap.put(columnindex, value);
continue;
}else{
//타입별로 value에 값을 넣어줍니다.
switch (cell.getCellType()){
case XSSFCell.CELL_TYPE_FORMULA:
value=cell.getCellFormula();
break;
case XSSFCell.CELL_TYPE_NUMERIC:
if( HSSFDateUtil.isCellDateFormatted(cell) ) {
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd");
value = formatter.format(cell.getDateCellValue());
}
else {
double ddata = Double.valueOf( cell.getNumericCellValue() ).intValue();
value = df.format(ddata);
}
break;
case XSSFCell.CELL_TYPE_STRING:
value=cell.getStringCellValue()+"";
break;
case XSSFCell.CELL_TYPE_BLANK:
value=cell.getBooleanCellValue()+"";
break;
case XSSFCell.CELL_TYPE_ERROR:
value=cell.getErrorCellValue()+"";
break;
}
}
//map에 데이터를 담습니다.
excelMap.put(columnindex, value);
System.out.println(rowindex+" 행 : "+columnindex+"번째의 값은: "+value);
}
}
}
//데이터 추출
model.addAttribute("excelList", excelList);
}catch(Exception e) {
e.printStackTrace();
}
return "tiles:bsite/bioresource/store/excelResultOne";
}
|
cs |
저는 엑셀 파일을 c드라이브에 위치한 file폴더에 넣어놨습니다. 이것을 사용하도록 FileInputStream에 넣어줍니다.
엑셀파일을 파싱하기 위해 POI라이브러리의 객체를 사용합니다. (HSSFWorkbook)
(파일이 xls일 경우 HSSFWorkbook로 사용하고, xlsx라면 XSSFWorkbook로 사용해야합니다!)
그리고 값을 담을 excelMap 과 담을 값을 리스트화 할 수 있는 excelList 를 생성합니다.
getSheetAt를 통해 데이터를 읽어옵니다.
getPhysicalNumberOfRows를 통해 행을 체크해주고
반복문을 통해 행의 수 만큼 반복을 해줍니다.
여기서 저는 3번째 행부터 데이터를 담기 위해서 if(rowindex > 2)를 사용했고
3번째 행이 되었을때 리스트에 값이 들어있는 맵값을 넣어주고, 다시 데이터를 담기 위해 맵을 초기화해줍니다.
행이 빈값이 아니면 셀의 수를 체크한 다음
셀의 수만큼 반복해줍니다.
셀이 NULL값이더라도 맵을 통해 빈값을 넣어주고 countinue로 다음 반복문을 실행해줍니다.
(빈칸도 다 나와야하니까요~)
NULL이 아닐 경우,
타입별로 구분하여 VALUE 변수에 넣어주고 마지막에 맵 객체에 데이터를 넣어줍니다.
콘솔을 찍어보면 잘 나오는 것을 확인할 수 있습니다.
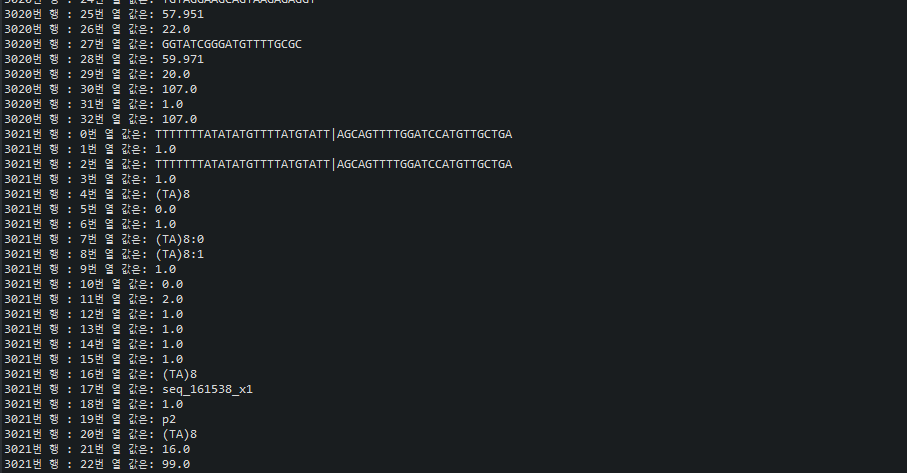
마지막에 MODEL을 통해 데이터를 추출해줍니다.
jsp
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
<div class="tab-content">
<h5 class="mt-4 ms-sm-1"><i class="bi bi-check-circle-fill"></i> Excel Result One</h5>
<div class="table_w mt-2 mCont_scroll">
<table id="resTb" class="table" name="tableStandard">
<colgroup>
<col style="width:6%">
<col />
<col style="width:6%">
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col />
<col style="width:6%">
<col />
<col />
<col style="width:6%">
<col />
<col />
<col />
<col />
<col />
</colgroup>
<thead>
<tr>
<th colspan="5">Sequence infomation</th>
<th colspan="5">stat 1 (SSR motif repeat number)</th>
<th colspan="6">stat2 (SSR motif existance)</th>
<th colspan="17">Primer3 result</th>
</tr>
<tr>
<th>Seq</th>
<th>IncludedSeqs_count</th>
<th>IncludedSeqs</th>
<th>SSR_Count</th>
<th>SSRs</th>
<th>group_A</th>
<th>group_B</th>
<th>group_A</th>
<th>group_B</th>
<th>P_value</th>
<th>group_A_Exist</th>
<th>group_A_NotExist</th>
<th>group_B_Exist</th>
<th>group_B_NotExist</th>
<th>P_value</th>
<th>Count</th>
<th>SSRs</th>
<th>ID</th>
<th>SSRnr.</th>
<th>SSRtype</th>
<th>SSR</th>
<th>size</th>
<th>start</th>
<th>end</th>
<th>FORWARDPRIMER0(5'-3')</th>
<th>Tm(째C)</th>
<th>size</th>
<th>REVERSEPRIMER1(5'-3')</th>
<th>Tm(째C)</th>
<th>size</th>
<th>PRODUCT0size(bp)</th>
<th>start(bp)</th>
<th>end(bp)</th>
</tr>
</thead>
<tbody>
<c:forEach var="result" items="${excelList}" varStatus="status">
<tr>
<c:forEach var="result2" items="${result}" varStatus="status2">
<td>${result2.value}</td>
</c:forEach>
</tr>
</c:forEach>
</tbody>
</table>
</div>
</div>
|
cs |
코드가 긴데... 저의 엑셀 데이터가 너무 크기때문에 테이블 해더가 많은 것 뿐입니다.
지우려다가 엑셀 데이터가 많으면 저렇게 해야한다는 예시로 남겨놨습니다..
중요한 부분은 tbody에 데이터 넣는 부분입니다.
자바에서 엑셀 데이터를 추출한 excelList 리스트를 어떻게 적용시킬까 하는 고민을 해야하죠!
우선 자바에서 가지고온 데이터의 형태는 이렇습니다.

즉, [{키-값, 키-값, 키-값, 키-값}] 이런 형태인거죠.
그래서 대괄호를 없애주기 위해서는 중첩 반복문을 해줍니다.
그러면 대괄호가 없어지고 {키-값, 키-값, 키-값, 키-값} 으로 데이터가 출력됩니다.
여기서 반복문 변수(result2)에 value를 선언하면 데이터 값을 추출(result2.value)할 수 있습니다.
'JAVA' 카테고리의 다른 글
| [JAVA] 객체지향 특징 및 Solid 원칙 정리!! (0) | 2021.12.08 |
|---|---|
| [Java] 엑셀 다운로드 기능 구현!! (영상 有) (6) | 2021.11.27 |
| [JAVA] RSA 암호화 방식 적용 방법 (0) | 2021.09.02 |
| [JAVA] 구글 OTP 구현 방법 (영상 有) (9) | 2021.09.01 |
| [JAVA] 두 날짜 데이터값 계산하는 방법 (faet.D-DAY 계산) (0) | 2021.08.01 |




댓글